
苹果已发布了FastVLM视觉语言模型,为新的智能眼
发布时间:2025-05-16 08:40
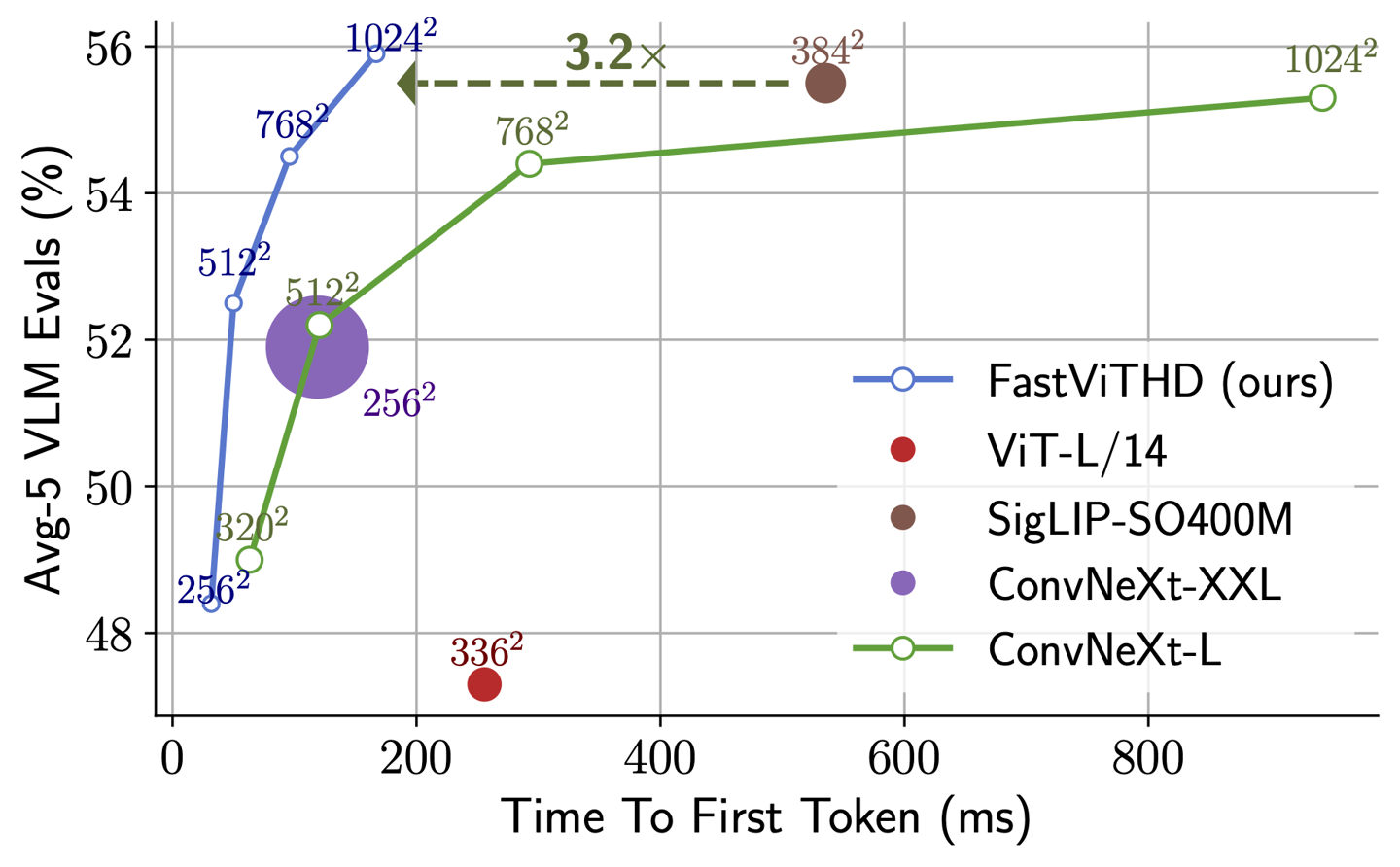 Home在5月13日报道说,Apple Machine研究团队上周在Github发行了视觉语言模型,即FastVLM,提供了三个版本:0.5B,1.5B和7B。据报道,该模型是根据Apple开发的MLX框架开发的,并在LLAVA代码基础的帮助下进行了培训,并针对Apple Silicon设备的终端操作进行了优化。技术文档表明,FastVLM以高分辨率的同时保持准确性的同时实现了近实时的图像处理,同时需要比类似模型更少的计算量。其核心是一种称为FastVithD的混合视觉编码器。苹果队说,编码器是“为高分辨率图像上的良好VLM性能设计的”,比类似型号快的速度快3.2倍,但只有三分之一的数量。突出显示FastVithD新的混合视觉编码器:专为高分辨率图像而设计,它可以减少令牌输出并大大缩短编码时间。模型版本的比较:比较G llava-onevision-0.5b模型达到了单词第一个元素(令牌)的速度的85倍,而视觉编码器的大小则是3.4倍。 QWEN2-7B语言模型的大版本:使用单个图像编码器意味着超过Cambrian-1-8B和其他最新研究结果,该单词元素响应的第一个速度已增加了iOS演示应用程序匹配的7.9倍:实际机器显示移动模型的性能。 Apple's technical team pointed out: "Based on comprehensive review of image resolution efficiency, visual delays, word element number and labI of LLM, we developed fastvlm- the model achieved the optimal trade-off between latency, model size and accuracy. Information from many parties shows Apple's plan to launch AI Benchmark Meta Ray-Bans glasses in 2027, and can release airpods devices with cameras at the same time. Foodvlm-local processing功能可以有效地支持此类设备以实现实时续远离视觉效果远非云。房屋查询发现,MLX框架使开发人员可以在Apple设备上训练和运行本地模型,同时与AI开发的主要语言兼容。 FastVLM的推出证明,苹果正在建立完整的终端AI生态系统技术。
Home在5月13日报道说,Apple Machine研究团队上周在Github发行了视觉语言模型,即FastVLM,提供了三个版本:0.5B,1.5B和7B。据报道,该模型是根据Apple开发的MLX框架开发的,并在LLAVA代码基础的帮助下进行了培训,并针对Apple Silicon设备的终端操作进行了优化。技术文档表明,FastVLM以高分辨率的同时保持准确性的同时实现了近实时的图像处理,同时需要比类似模型更少的计算量。其核心是一种称为FastVithD的混合视觉编码器。苹果队说,编码器是“为高分辨率图像上的良好VLM性能设计的”,比类似型号快的速度快3.2倍,但只有三分之一的数量。突出显示FastVithD新的混合视觉编码器:专为高分辨率图像而设计,它可以减少令牌输出并大大缩短编码时间。模型版本的比较:比较G llava-onevision-0.5b模型达到了单词第一个元素(令牌)的速度的85倍,而视觉编码器的大小则是3.4倍。 QWEN2-7B语言模型的大版本:使用单个图像编码器意味着超过Cambrian-1-8B和其他最新研究结果,该单词元素响应的第一个速度已增加了iOS演示应用程序匹配的7.9倍:实际机器显示移动模型的性能。 Apple's technical team pointed out: "Based on comprehensive review of image resolution efficiency, visual delays, word element number and labI of LLM, we developed fastvlm- the model achieved the optimal trade-off between latency, model size and accuracy. Information from many parties shows Apple's plan to launch AI Benchmark Meta Ray-Bans glasses in 2027, and can release airpods devices with cameras at the same time. Foodvlm-local processing功能可以有效地支持此类设备以实现实时续远离视觉效果远非云。房屋查询发现,MLX框架使开发人员可以在Apple设备上训练和运行本地模型,同时与AI开发的主要语言兼容。 FastVLM的推出证明,苹果正在建立完整的终端AI生态系统技术。 下一篇:没有了